
在前一篇eBPF: Attach Go(Part0): Go 语言基础和特性中介绍了Go语言的基础类型和接口的实现。而接下来本文将围绕Go语言的ABI规范展开介绍,简单来说有如下两个结论:
-
在 Go1.17 之前,Go函数调用约定为通过栈传递参数(stack-based);
-
从 Go1.17 开始,Go将函数调用的方式从栈传递参数切换成寄存器传递参数(register-based),当寄存器无法满足存储参数时,则剩余的在堆栈上传递。
0.Call Convention
为什么要了解函数调用约定(Call Convention)呢 ? 当我们在使用libbpf attach函数时,通常会使用如PT_REGS_PARM1这样的宏来访问函数参数,查看源码可以发现其实最终是访问了对应的寄存器,比如展开可能是AX,BX,DI……
|
|
当然,这些宏实际上是libbpf根据C语言的ABI为C设置的。当我们使用eBPF去获取Go的函数参数、返回值时,我们就需要知道这些值是谁存放的?如何存放的?又存放在哪里?从那里取?即调用约定指的是函数调用时参数传递、返回值处理和堆栈管理的规定和约定。比如在C/C++中有以下调用约定:
| 关键字 | 堆栈清理 | 参数传递 |
|---|---|---|
| __cdecl | 调用方 | 在堆栈上按相反顺序推送参数(从右到左) |
| __clrcall | 不适用 | 按顺序将参数加载到 CLR 表达式堆栈上(从左到右)。 |
| __stdcall | 被调用方 | 在堆栈上按相反顺序推送参数(从右到左) |
| __fastcall | 被调用方 | 存储在寄存器中,然后在堆栈上推送 |
| __thiscall | 被调用方 | 在堆栈上推送;存储在 ECX 中的 this 指针 |
| __vectorcall | 被调用方 | 存储在寄存器中,然后按相反顺序在堆栈上推送(从右到左) |
tips: 函数调用约定如果展开讲的话,还是有很多东西需要深入学习的。
1.Issue#40724
Proposal: Register-based Go calling convention
Proposal: Create an undefined internal calling convention
Issue#40724: switch to a register-based calling convention for Go functions
接下来,我们看一下Go中的ABI,首先先了解一下#40724这个issue都讨论了些什么。
Go 自发布以来一直使用的都是基于堆栈式的Plan 9 ABI 函数调用约定(显然,Plan9和Rob Pike有关系)。这种在堆栈上通过值传递的方式优势是:调用规则简单,并且这种规则是建立在现有的结构布局规则之上的;且在所有平台上都可以使用相同的约定从而保持可移植的编译器和运行时程序…..而且由于旧的ABI没有用到寄存器,这也简化了在panic时对垃圾回收、堆栈增长和堆栈展开的跟踪。
虽然基于堆栈的函数调用约定简单,但是在性能上也存在许多问题。毕竟访问寄存器总是要比访问堆栈要快得多(约40%),即使现在CPU已经尽力在对堆栈进行了优化。
因而,issue#40724 建议将Go ABI 切换至基于寄存器的函数调用约定:
-
不使用操作系统平台的调用约定,虽然它在不同语言间的调用上更有效。但Go最核心的特性就是协程,而协程是由Go运行时调度的而非操作系统内核调度(非线程),且协程的堆栈在运行时是可动态调整的。
-
大多数现有的ABI都是基于C语言的,当然这也很语言特性有关。比如Go的切片
{data, len, cap}在现有的x86_64/arm64/RISC-V等上会强制使用堆栈传递而不是寄存器。同样问题在返回值上,Go的函数返回值通常有多个(通常会有error),而C基本上是一个,这导致Go的返回值会被放在堆栈上而不是寄存器。因此,平台abi并不适合Go语言。
2.Stack-based(ABI0)
基于堆栈式的函数调用约定。ABI0参数完全通过堆栈传递,参数列表从右向左依次压栈(栈的生长方向右高地址向低地址),返回值亦在栈上传递。从高地址到低地址,栈的布局是:局部变量–返回值—参数列表。函数参数和返回值的大小以及对齐问题和结构体的大小和成员对齐问题是一致的,函数的第一个参数和第一个返回值会分别进行一次地址对齐。(足以见得ABI0方式的简单)
3.Register-based(ABIInternal)
基于寄存器的函数调用约定使用堆栈和寄存器的组合来传递参数和结果。每个参数或结果要么完全在寄存器中传递,要么完全在堆栈中传递。因为访问寄存器通常比访问堆栈快,所以参数和结果优先在寄存器中传递。但是,任何包含非平凡数组或不完全装入剩余可用寄存器的参数或结果都会在队栈上传递。
参数和结果可以共享相同的寄存器,但不能共享相同的堆栈空间。除了在堆栈上传递的参数和结果之外,调用方还在堆栈上为所有基于寄存器的参数保留溢出空间(但不填充该空间)。
分配一个底层类型为T的接收者、参数或结果V的工作方式如下:
-
T是适合整型寄存器的布尔或整型类型,则将V分配给寄存器I并自增;
-
T是适合两个整数寄存器的整型,则将V的最低有效位和最高有效位分别分配给寄存器I和I+1,并将I增加2;
-
T是浮点类型并且可以在浮点寄存器中不损失精度地表示,则将V分配给寄存器FP,并递增FP;
-
T是一个复数类型,则递归地寄存器分配它的实部和虚部;
-
T是指针类型、映射类型、通道类型或函数类型,则将V分配给寄存器I并自增;
-
T是字符串类型、接口类型或切片类型,则递归地对V的组件分配寄存器(2个用于字符串和接口,3个用于切片);
-
T是结构体类型,则递归地为V的每个字段分配寄存器;
-
T是长度为0的数组类型,则什么也不做;
-
T是长度为1的数组类型,则递归地为它的每一个元素分配寄存器;
-
T是长度大于1的数组类型,则分配失败;
-
如果上述任何递归赋值失败,则失败。
最终的堆栈序列看起来像:堆栈分配的接收器、堆栈分配的参数、指针对齐、堆栈分配的结果、指针对齐、每个寄存器分配的参数的溢出空间、指针对齐。下图显示了这个堆栈帧在堆栈上的样子,使用了地址0位于底部的典型约定:
|
|
3.1amd64 architecture
在amd64架构下,Go ABIInternal使用以下9个寄存器来存储整型参数和结果(不过在Go的反汇编中RAX等是不带R的,直接使用AX表示),使用X0 - X14存储浮点参数和结果:
|
|
对于栈增长和反射调用等一些特定操作需要借助专用的暂存寄存器,以便在不破坏参数或结果的情况下操作调用帧。专用寄存器如下:
| Register | Call meaning | Return meaning | Body meaning |
|---|---|---|---|
| RSP | Stack pointer | Same | Same |
| RBP | Frame pointer | Same | Same |
| RDX | Closure context pointer | Scratch | Scratch |
| R12 | Scratch | Scratch | Scratch |
| R13 | Scratch | Scratch | Scratch |
| R14 | Current goroutine | Same | Same |
| R15 | GOT reference temporary if dynlink | Same | Same |
| X15 | Zero value (*) | Same | Scratch |
表来源: https://github.com/golang/go/blob/master/src/cmd/compile/abi-internal.md
Tips: 可以直接被拿来用的寄存器叫scratch register, 需要保护才能使用的寄存器叫volatile register;相对而言scrach register也叫non-volatile register, volatile register也叫preserved register。
-
其中,R14被指定为固定寄存器,用于存储当前goroutine指针;
-
另外,X15被指定为固定零寄存器,因为函数通常必须将其栈帧批量归零,而使用指定的零寄存器更高效。
在堆栈布局中,堆栈指针RSP向下增长,并始终对齐为8字节,amd64体系结构不使用链接寄存器,一个函数的栈帧布局如下:
|
|
-
return PC作为标准amd64CALL的一部分被压入堆栈; -
进入函数时,从RSP中减去RBP,打开它的堆栈帧,并将RBP的值保存在
return PC的下方。
3.2arm64 architecture
在arm64架构下,Go ABIInternal使用R0 - R15存储整型参数和结果,使用F0 - F15存储浮点参数和结果。专用寄存器如下:
| Register | Call meaning | Return meaning | Body meaning |
|---|---|---|---|
| RSP | Stack pointer | Same | Same |
| R30 | Link register | Same | Scratch (non-leaf functions) |
| R29 | Frame pointer | Same | Same |
| R28 | Current goroutine | Same | Same |
| R27 | Scratch | Scratch | Scratch |
| R26 | Closure context pointer | Scratch | Scratch |
| R18 | Reserved (not used) | Same | Same |
| ZR | Zero value | Same | Same |
在堆栈布局中,堆栈指针RSP向下增长,并始终对齐为16字节(arm64架构要求堆栈指针以16字节对齐),一个函数的栈帧布局如下:
|
|
-
作为arm64
CALL操作的一部分,return PC被加载到R30寄存器中; -
进入函数时,从RSP中减去RSP打开它的堆栈帧,并将R30和R29的值保存在帧的底部;其中RSP更新后,R30保存在0(RSP), R29保存在-8(RSP)。
关于riscv64等其他架构可查阅/src/cmd/compile/abi-internal.md原文。
4.Example: ABI0 Vs ABIInternal
我们先编写一个简单函数来看一下两种ABI的函数调用方式,代码如下:
|
|
我们在Go1.16.1下执行GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go反汇编得如下:
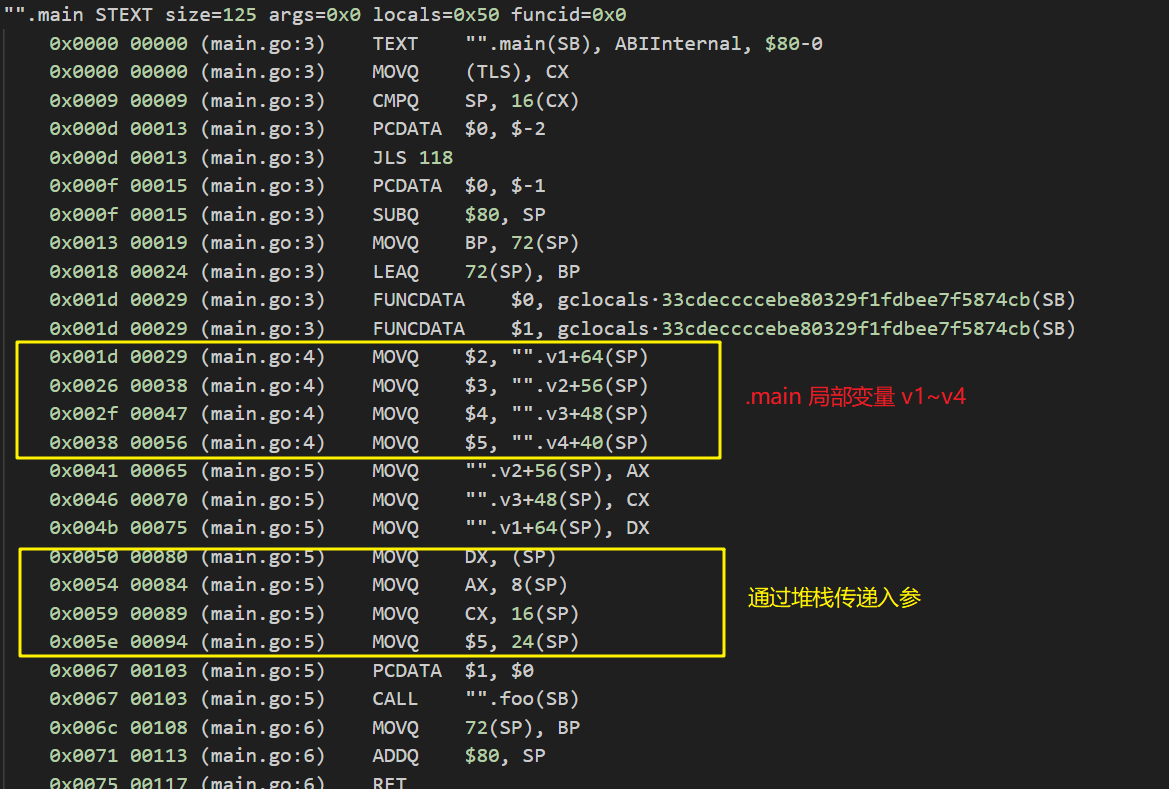
再看一下func foo(a1, a2, a3, a4 int64) int64函数的反汇编代码:
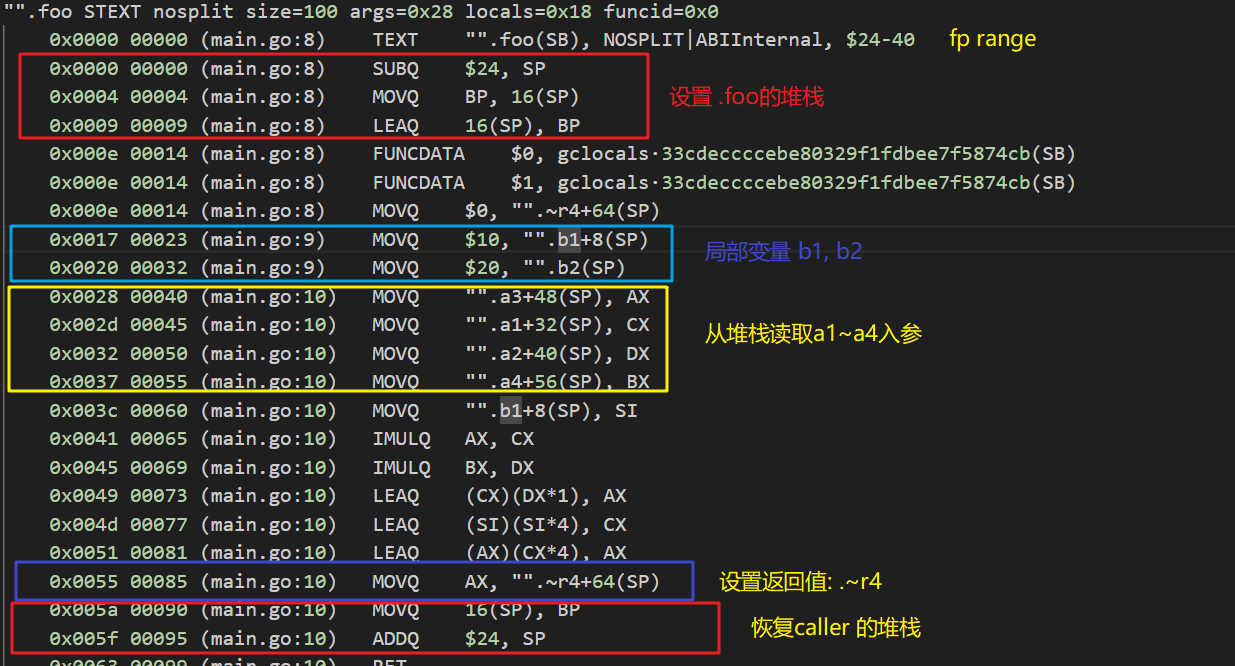
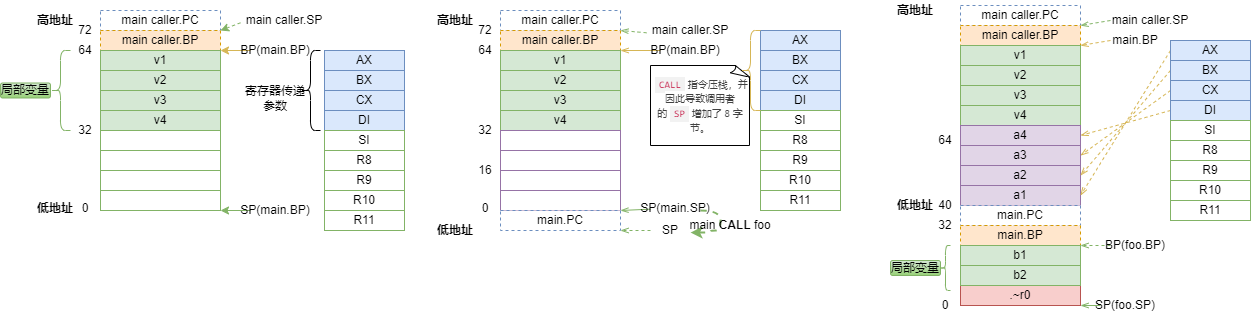
通过ABI0的定义和上述汇编代码,我们可以得到main函数调用foo时的堆栈切换:
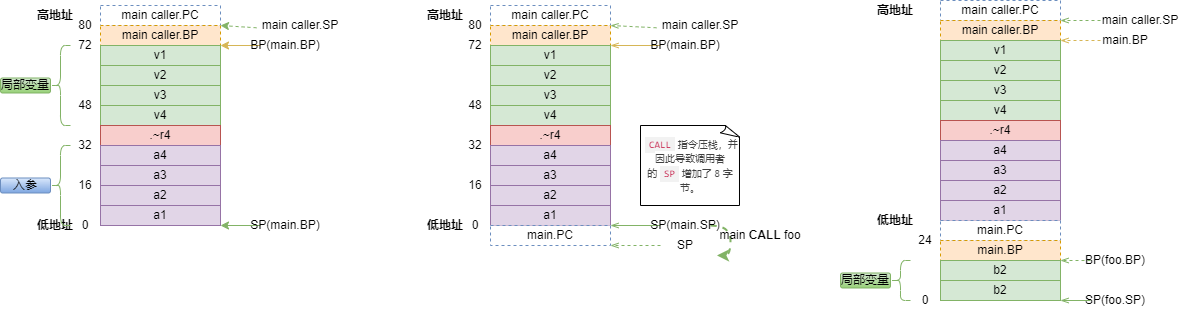
当CALL指令执行时,会压栈caller的PC,上图即main.PC导致SP+8;
-
在x86架构下使用eBPF attach uprobe时,即会在函数入口处插入
INT3中断汇编指令,即对应截图中设置.foo堆栈前(即上图中间的堆栈示例),那么,此时通过SP获取函数的入参即:-
a1 即 (SP+8);
-
a2 即 (SP+16);
-
a3 即 (SP+24);
-
a4 即 (SP+32);
-
~r4返回值即(SP+40).
-
接下来切换至Go1.20.7看看ABIInternal的函数调用方式,同样执行GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go反汇编得如下:
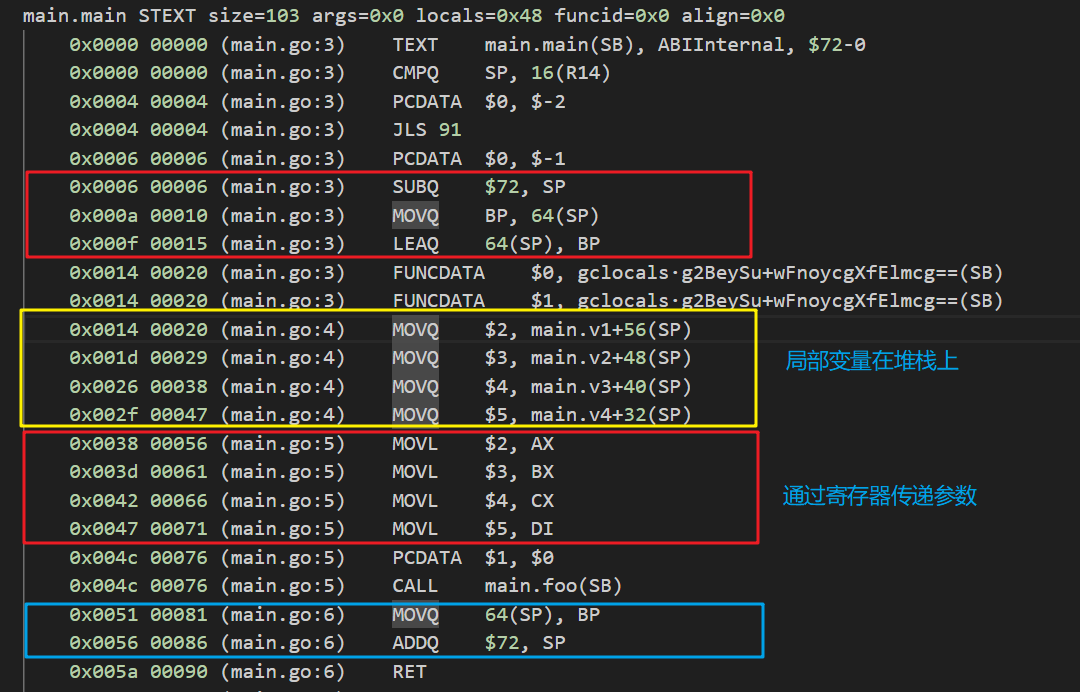
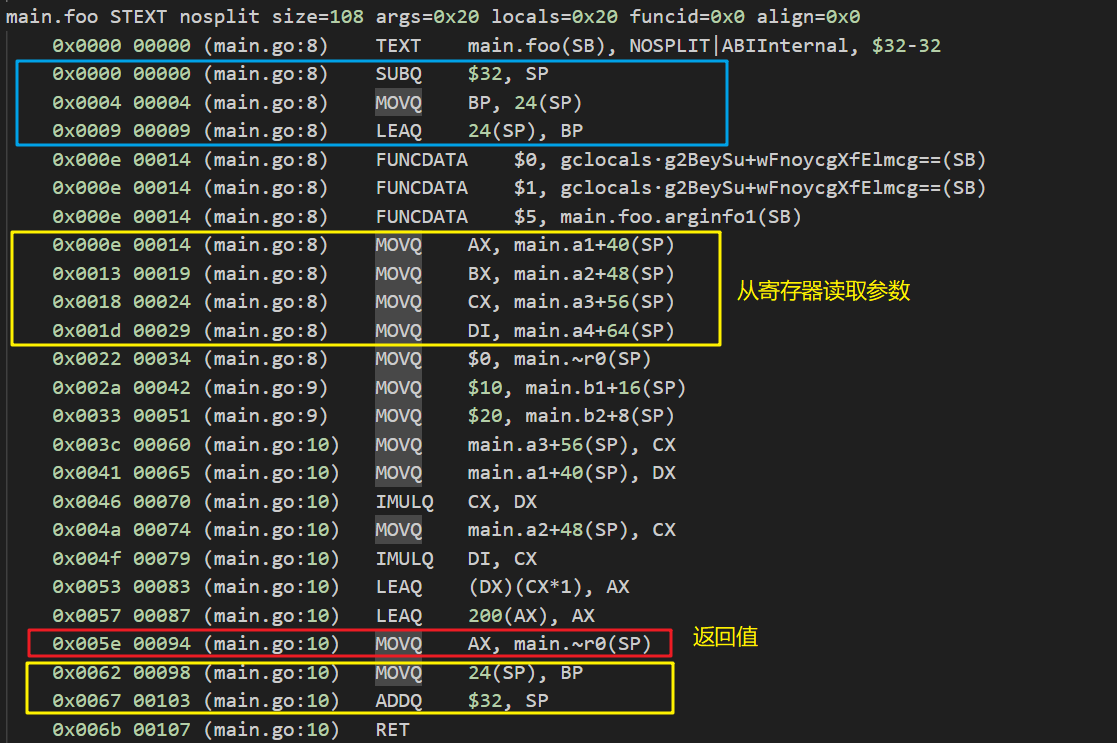
可以得到如下的堆栈变化图:
5.eBPF: Howto Get Go parameters ?
上面的例子从汇编代码的角度演示了两种ABI的函数调用过程,那么根据Go的ABI规范我们可以在eBPF程序中按照约定获取函数的参数和返回值:
|
|
可以把上面寄存器排列看成一个数组regs,对于堆栈,其本身就类似数组,那么,我们有:
|
|
|
|
6.Conclusion
在Go 1.17 Release Notes#Compiler小节中有提到:Go的函数调用方式从基于栈传递参数切换至基于寄存器传递参数的方式后,获得了约 5% 的性能和 2% 的二进制文件缩小。
Go从1.17.1版本,开始支持多ABI,主要是两个ABI:ABI0和ABIInternal。值得注意的是:ABIInternal似乎是不稳定的ABI。
对于ABI0,我们很容易就能通过SP获取到参数和返回值,需要注意的是eBPF的uprobe放置在函数入口处,这是CALL指令已经将SP+8,所以获取第一个参数为SP+8。
对于ABIInternal要稍微复杂一些,我们将9个寄存器看作一个char数组,通过参数的offset来访问。只需要记住当寄存器能满足参数或返回值的存储时,第i个参数或第i个返回值的,可通过regs+offset,比如第一参数为int时为regs+0对应AX寄存器。特别需要注意的是,当参数或返回值过多或寄存器大小无法满足时,ABIInternal会使用堆栈来传递参数或返回值。就可能会出现一个参数或返回值恰好同时跨越寄存器和堆栈,但这种情况时不会存在的。比如[]byte的结构是{data,len,cap},不会出现data和len通过寄存器传递而cap通过堆栈传递,如果出现同时跨越的情况,那么将该参数将会全部通过堆栈传递,即{data,len,cap}都通过堆栈传递。
另外,在传递参数和返回值时,还需特别注意考虑内存对齐问题。
7.Links
Proposal: Register-based Go calling convention
Proposal: Create an undefined internal calling convention
Issue#40724: switch to a register-based calling convention for Go functions