
2024年3月初
简明扼要地说,这是一本适合eBPF入门者学习的书籍,当然也适合有一定经验的eBPF开发者翻阅补充可能缺失的知识。至于我,因为我本身处于后者,所以读起来很快而且大部分的知识都已掌握,所以并不会给出很高的评分。但是,毕竟是 ebpf.io 上推荐的书籍加上本身 eBPF 的书籍也并不多(暂且),所以该翻阅还是翻阅了。
我认为,对于前面几章关于 BPF 的知识,主要关注点应该放在一些细节上,比如 BPF 验证器会具体做哪些事?BPF 各种程序类型已经很丰富了,想想哪些地方可以应用呢?BPF 映射有什么不同和使用场景呢?
越是学习 eBPF,就越有一种感觉:eBPF本身是 Linux 内核技术上的创新,但也不是能解百病的良丹妙药,它是一种手段,是作为解决某类问题的奇招。比如使用 eBPF 对网络进行观测时,对 TCP/IP 协议栈在内核中的调用流程比 eBPF 本身更具价值,当然你肯定也需要对 eBPF 有所熟悉,但我要说的是在解决问题中,前者才是主要的,eBPF 只是作为一种高效的手段。其实,仔细想想,实际工作中,工程师不也是为解决业务问题而服务的,一切以业务为先。
刚好,绘制了一张自己 eBPF 学习路线的思维导图,因为之前 XDP 没有怎么关注过,交流群里的大佬经常提及,所以我单独列出来,准备下阶段学习。其他,再分散的话,那就要聚焦到具体的应用场景了,网络、安全(特别是云原生安全)、可观测、跟踪等等,阅读开源项目应该是最好的实践方法。
思维导图:
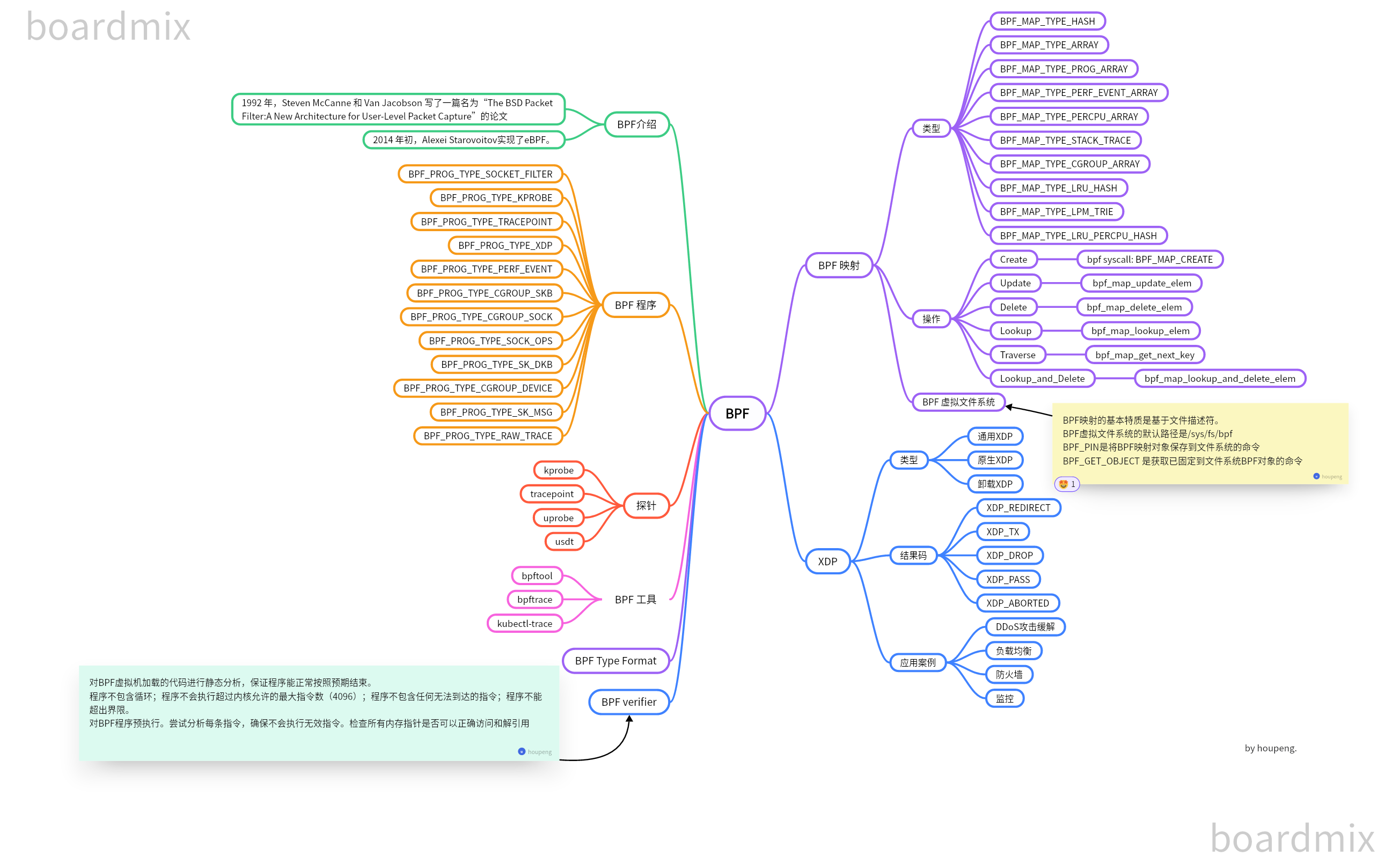
eBPF学习计划:
 https://boardmix.cn/app/share/CAE.COaN-QwgASoQzPvcP3XpSe2G_tyukgFb9TAGQAE/KR46DN
https://boardmix.cn/app/share/CAE.COaN-QwgASoQzPvcP3XpSe2G_tyukgFb9TAGQAE/KR46DN
BPF
1992 年,Steven McCanne 和 Van Jacobson 写了一篇名为“The BSD Packet Filter:A New Architecture for User-Level Packet Capture”的论文。
2014 年初,Alexei Starovoitov实现了eBPF。
BPF验证器,BPF验证器添加了必需的安全保障。它能确保任何BPF程序运行完成,不会造成系统的崩溃,并且它确保程序不会出现内存溢出。这得益于对BPF 程序的限制,例如,程序大小的最大限制和循环的限制,以确保不会因为BPF 程序错误,而产生系统内存溢出。
bpf 系统调用用于用户空间和内核之间的通信。
BPF映射是内核与用户空间交换数据的主要机制,负责在两者之间共享数据
BPF程序编译后,内核通过bpf系统调用将程序字节码加载到BPF虚拟机中。
BPF Program
BPF 程序类型:
跟踪 了解系统正在发生什么
网络 检测和控制系统中的网络流量 数据包过滤、拒绝数据包…
1. BPF_PROG_TYPE_SOCKET_FILTER 套接字过滤器程序
套接字过滤器程序会附加到原始套接字上,用于访问所有套接字处理的数据包。套接字过滤器程序只能用于对套接字的观测,不允许修改数据包内容或更改目的地。
2. BPF_PROG_TYPE_KPROBE kprobe程序
kprobe 时动态附加到内核调用点的函数。BPF kprobe 程序类型允许使用 BPF 程序作为kprobe 的处理程序。
3. BPF_PROG_TYPE_TRACEPOINT Tracepoint 跟踪点程序
跟踪点时内核代码的静态标记,允许注入跟踪和调试相关的任意代码。
系统的所有跟踪点都定义在:/sys/kernel/debug/tracing/events
4. BPF_PROG_TYPE_XDP XDP程序
当网络包到达内核时,XDP程序会在早期被执行。在这种情况下,因为内核还没有对数据包本身进行太多处理,所以显示数据包的信息有限。但因为在初期执行,意味着程序对数据的处理具更高级别的控制。XDP应用实现防御DDos攻击。
5. BPF_PROG_TYPE_PERF_EVNET Perf事件程序
perf事件程序将BPF代码附加到Perf事件上。
Perf 时内核的内部分析器,可以产生硬件和软件的性能数据事件。
6. BPF_PROG_TYPE_CGROUP_SKB cgroup套接字程序
cgroup套接字程序可以将BPF逻辑附加到控制组(cgroup)上。该程序允许cgroup在其包含的进程中控制网络流量。附加到cgroup控制的所有进程上,而不是特定的进程。
7. BPF_PROG_TYPE_CGROUP_SOCK cgroup 打开套接字程序
这种程序类型允许cgroup内的任何进程打开网络套接字时执行代码。这种程序可以对打开套接字的程序组提供安全性和访问控制,而不必单独限制每个进程的功能。
8. BPF_PROG_TYPE_SOCK_OPS 套接字选项程序
当数据包通过内核网络栈的对各阶段中转时,这种类型程序允许运行时修改套接字连接选项。
9. BPF_PROG_TYPE_SK_SKB 套接字映射程序
这种程序可以访问套接字映射和套接字重定向。这种程序类型可以实现负载均衡功能Cillium项目以及facebook的katran项目广泛利用这种程序类型实现对网络流量进行控制。
BPF_PROG_TYPE_CGROUP_DEVICE cgroup设备程序
实现允许为特定设备设置权限。
BPF_PROG_TYPE_SK_MSG 套接字消息传递程序
当内核创建一个套接字时,会将套接字存储在上面提到的套接字映射中。
BPF_PROG_TYPE_RAW_TRACE 原始跟踪点程序
cgroup 套接字地址程序 TYPE_CGROUP_SOCK_ADDR
BPF尾部调用 BPF程序可以使用尾部调用来调用其他BPF程序。
BPF verifier
eBPF验证器是eBPF程序与毁灭的深渊之间的分水岭。
检查1:对BPF虚拟机加载的代码进行静态分析,保证程序能够按照预期结束。
程序不包含控制循环。为确保程序不会陷入无限循环,验证器将拒绝任何类型的控制循环。
程序不会执行超过内核允许的最大指令数。4096?5.2 之后100万条。程序不包含任何无法到达的指令。程序不能超出程序界限。
检查2:对BPF程序执行预运行。尝试分析程序执行的每条指令,确保不会执行无效指令。检查所有内存指针是否可以正确访问和解引用。
BPF Type Format
BPF类型格式(BTF)是元数据结构的集合。BTF可用来增强BPF程序、映射和函数的调试信息。
BPF Map
BPF映射以键值保存在内核中,可以被任何BPF程序访问。用户空间的程序也可以通过文件描述符访问BPF映射。BPF映射中可以保存事先指定大小的任何类型的数据。内核讲键和值作为二进制块,这意味着内核并不关心BPF映射保存的具体内容。
操作 BPF 映射
Create
创建BPF映射最直接方式是使用bpf系统调用。如果该系统调用的第一个参数设置为BPF_MAP_CREATE,则表示创建一个新的映射。该调用将返回与创建映射相关的文件描述符。第二个参数是BPF映射的设置,第三个参数是设置属性的大小。
Update
内核程序从bpf/bpf_bpfhelpers.h 加载 bpf_map_update_elem 用户空间程序从lib/bpf/bpf.h 加载 bpf_map_update_elem
内核程序可以直接访问映射,而用户空间程序需要使用文件描述符来引用映射。BPF_ANY BPF_NOEXIST BPF_EXIST
Lookup
bpf_map_lookup_elem
Delete
bpf_map_delete_elem
Traverse
bpf_map_get_next_key ,仅适用于用户空间上运行的程序。
Lookup_and_Delete
bpf_map_lookup_and_delete_elem 在映射中查找指定的键并删除元素。
并发访问映射元素
未来防止竞争条件,BPF 引入了BPF自旋锁的概念,可以在操作映射元素时对访问的映射元素进行锁定,自旋锁仅适用于数组、哈希、cgroup存储映射。
BPF 映射类型
BPF_MAP_TYPE_HASH 哈希表映射
该映射可以使用任意大小的键和值,内核会按需分配和释放它们。
BPF_MAP_TYPE_ARRAY 数组映射
数组映射时添加到内核中的第二个BPF映射。对数组映射初始化时,所有元素在内存中将预分配空间并设置为0。因为映射由切片元素组成,键是数组中的索引,大小必须签好为四个字节。使用数组映射的一个缺点是映射中的元素不能删除,无法使用数组变小。如果在数组映射上使用bpf_map_delete_elem调用将失败,得到EINVAL错误。数组映射通常用于保存值可能会更新的信息,但是行为通常固定不变。
BPF_MAP_TYPE_PROG_ARRAY 程序数组映射
程序数组映射是添加到内核的第一个专用映射。这种类型保存对BPF程序的引用,即BPF程序的文件描述符。于辅助函数bpf_tail_call 结合使用,可以实现程序之间跳转,突破单个BPF程序最大指令限制,并且减低实现的复杂性。键和值的大小都必须是为4个字节。当跳到新程序时,新程序将使用相同的内存栈,因此程序不会耗尽所有有效的内存。如果跳转到映射中不存在的程序,尾部调用将失败,返回继续执行当前程序。
BPF_MAP_TYPE_PERF_EVENT_ARRAY Perf事件数组映射
这种类型映射将perf_events数据存储在环形缓存区中,用于BPF程序和用户空间程序进行实时通信。
BPF_MAP_TYPE_PERCPU_ARRAY 单CPU数组映射
是数组映射的改进版,我们可以给该类型映射分配CPU,那么每个CPU会看到自己独立的映射版本,对于高性能查找和聚合更有效。
BPF_MAP_TYPE_STACK_TRACE 栈跟踪映射
这种类型的映射保存运行进程的栈跟踪信息。内核添加了辅助函数bpf_get_stackid用来帮助将栈跟踪信息写入该映射。
BPF_MAP_TYPE_CGROUP_ARRAY cgroup 数组映射
类似于BPF_MAP_TYPE_PROG_ARRAY,只是它们存储指向cgroup的文件描述符。当你要在BPF映射之间共享cgroup引用控制流量、调试和测试时,这种类型映射非常有用。
BPF_MAP_TYPE_LRU_HASH LRU BPF_MAP_TYPE_LRU_PERCPU_HASH
这两种映射都是哈希表映射,同时还实现了内部LRU缓存。即最近最少使用。
BPF_MAP_TYPE_LPM_TRIE LPM Tire 映射
LPM Tire映射使用最长前缀匹配LPM算法来查查找映射元素。该映射要求键大小为8的倍数,范围从8到2048,如果不想实现自己的键,内核提供了bpf_lpm_trie_key的结构。
BPF 虚拟文件系统
BPF映射的基本特质是基于文件描述符,这意味着关闭文件描述符后,映射及其所保存的所有信息都会消失。
BPF虚拟文件系统的默认目录时/sys/fs/bpf。与其他文件系统层次结构一样,保存在文件系统中的持久化BPF对象通过路径来标识。
BPF_PIN_FD是将BPF对象保存到文件系统的命令。命令执行成功后,该对象将在文件系统指定的路径可见。
BPF_OBJ_GET是获取已固定到文件系统BPF对象的命令。该命令使用分配给对象的路径来加载BPF对象。
BPF 跟踪
在软件工程中,跟踪是一种为了进行分析和调试而手机数据的方法。使用BPF跟踪的优点:
-
几乎可以访问Linux内核和应用程序的任何信息
-
对系统性能和延迟造成的开销最小
-
不需要修改程序
探针:
-
内核探针 kprobe:提供对内核中内部组件的动态访问。
-
跟踪点 tracepoint:提供对内核中内部组件的静态访问。
-
用户空间探针 uprobe:提供对用户空间运行的程序的动态访问
-
用户静态定义跟踪点USDT:给用户空间运行的程序的静态访问。
kprobes
内核探针几乎可以在任何内核指令上设置动态标志或中断。内核探针没有稳定的ABI,意味着它们可能会随着内核版本的演进而更新
tracepoint
跟踪点是内核代码的静态标记,可用于将代码附加在运行的内核中。由于跟踪点是静态存在的,所以跟踪点的ABI更稳定。考虑到跟踪点添加时由内核开发人员添加的,所以跟踪点可能并不能涵盖到内核的的所有子系统。
查看系统所有的可用跟踪点:/sys/kernel/debug/tracing/events
uprobes
用户空间探针允许在用户空间运行的程序中设置动态标志。当我们定义uprobe时,内核会在附加的指令上创建陷阱。当程序执行到该指令时,内核将出发事件以回调函数的方式调用探针函数。
BPF 工具
bpftool
bpftool 是一个用于检测BPF程序和映射的内核工具。
查看系统可访问的BPF特性:
bpftool feature
检查系统中运行的BPF程序:
bpftool prog show
bpftool prog show id 32
统计内核在 BPF 程序上花费的时长:
sysctl -w kernel.bpf_stats_enabled=1
检查 BPF 映射
bpftool map show
创建 BPF 映射元素
bpftool map create /sys/fs/bpf/couter type array key 4 value 4 entries 5 name counter
查看附加到特定接口的程序
perf 子命令可以列出系统中附加到跟踪点的所有程序。
显示程序加载的所有BTF类型:
bpftool btf dump id 54
bpftrace
。。。
kubectl-trace
kubectl-trace是Kubernetes命令行工具kubectl的一个非常好的插件。
网络与BPF
从网络的角度看,使用BPF程序主要有两个用途:数据包捕获和过滤。这意味着用户空间的程序可以将过滤器附加到任何套接字,并能够提取流经数据包的相关信息,同时能够对查看到的某些类型和数据包放行、禁止或重定向等。
过滤器主要用于3种高级情景:
实时流量丢弃(例如:仅允许用户数据报协议UDP流量,并丢弃其他类型的数据包)。
实时观测特定条件过滤后的数据包
对实时系统中抓取的网络流量进行后续分析,例如使用pacap格式进行分析。
流量控制是内核数据包调度子系统架构。它由工作机制和排队系统组成,用来决定如何传递和接收数据包。比如:
- 优先处理某些类型的数据包
- 丢弃特定类型的数据包
流量控制
排队规则(qdisc)定义了调度对象,该对象通过更改数据包的发送方式使进入接口的数据包排队,这些对象可以是无分类的也可以是有分类的。 默认的排队规则是pfifo_fast,它是无分类的,将数据包进入3个FIFO队列中,并基于优先级出队。这个排序规则不适用于使用noqueue的虚拟设备,比如回环接口lo或虚拟以太网设备veth。
何时使用 XDP 代替流量控制更有优势。答案是,由于XDP 不包含所有内核丰富的数据结构和元数据,所以 XDP 程序更适合于覆盖OSI层到第4层的场景。
XDP
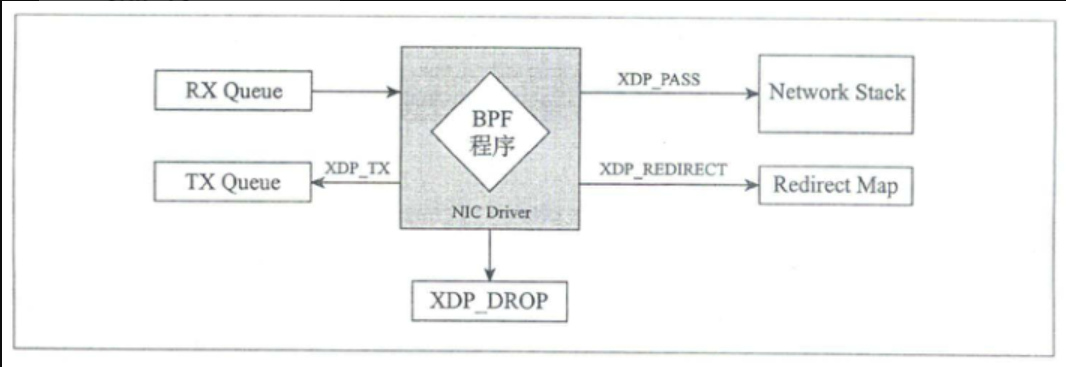
XDP是Linux网络数据路径上内核集成的数据包处理器,具有安全、可编程、高性能的特点。当网卡却动程序收到数据包时,该处理器执行BPF程序。这使得XDP程序可以在最早的事件点,对接收到的数据八篇进行丢弃、修改或允许等操作。
使用XDP进行数据包处理时,没有内存分配。
XDP程序仅适用于线性的、无碎片的数据包,并且有数据包的头指针和尾指针。
XDP程序无法访问完整的数据包元数据,这种程序接受的输入上写文时xdp_buff类型,而不是sk_buff结构。
如果一个BPF程序使用XDP框架提供的直接数据包访问机制,xdp_buff结构用于为该BPF程序呈现数据包上下文。xdp_buff结构可视为sk_buff的“轻量化”版本、两者之间的区别在于:
- sk_buff 保留数据包的元数据,允许与这些数据包的元数据(原型、标记和类型)联合使用。
- xdp_buff 创建很早,不依赖其他内核层,所以XDP可以更快地获得和处理数据包。
- xdp_buff与使用sk_buff地程序类别有所差异,xdp_buff不保存对路由、流量控制狗子或其他类型地数据包元数据地引用。
XDP程序概述
本质上XDP程序所做的是对接收的数据包进行决策,然后对接收的数据包内容进行编辑或者只返回一个结果码。 XDP与eBPF? XDP程序是通过bpf系统调用进行控制的,使用程序类型BPF_PROG_TYPE_XDP进行加载。 XDP有三种操作模式:原生XDP、卸载XDP、通用XDP。
-
原生XDP:在这种模式下,XDP的BPF程序在网络驱动程序的早期接收路径之外直接运行。使用此模式时需要检查驱动程序是否支持此模式。
-
卸载XDP:在这种模式下,XDP的BPF程序直接卸载到网卡上,而不是在主机CPU上执行。因为将执行从CPU上移除,所以这种模式比原生XDP具有更高的性能。
-
通用XDP:通用模式XDP是一种测试模式,内核从版本4.12开始支持通用XDP。
XDP数据包处理器可以在XDP数据包上执行BPF程序,并协调BPF程序和网络栈之间的交互。数据包处理器是XDP程序的内核组件,一旦数据包被网卡接收,数据包处理器直接处理接收RX队列上的数据包。数据包处理器保证数据包是可读可写的,并允许以操作的形式附加处理后决策,数据包处理器可以在运行时原子性地更新程序和加载新程序,并不会导致网络和相关流量中断服务。
XDP 结果码
-
丢弃 XDP_DROP:丢弃数据包,这发生在驱动程序的最早RX阶段。丢弃数据包仅意味着将数据包回收到刚刚“到达”的RX环形队列中。对于降低Dos场景而言,尽早丢弃数据包是关键。
-
转发 XDP_TX:转发数据包,这可能在数据包被修改前或修改后发生。抓饭数据包意味着将接收到的数据包发送回数据包到达的同一网卡。
-
重定向 XDP_REDIRECT:于XDP_TX相似,重定向也用于传递XDP数据包,但是重定向是通过另一网卡传输或者传入到BPF的cpumap中。
-
传递 XDP_PASS:将数据包传递到普通网络栈进行处理。
-
错误XDP_ABORTED:表示eBPF程序错误,并导致数据包被丢弃。程序不应该将它作为返回码。
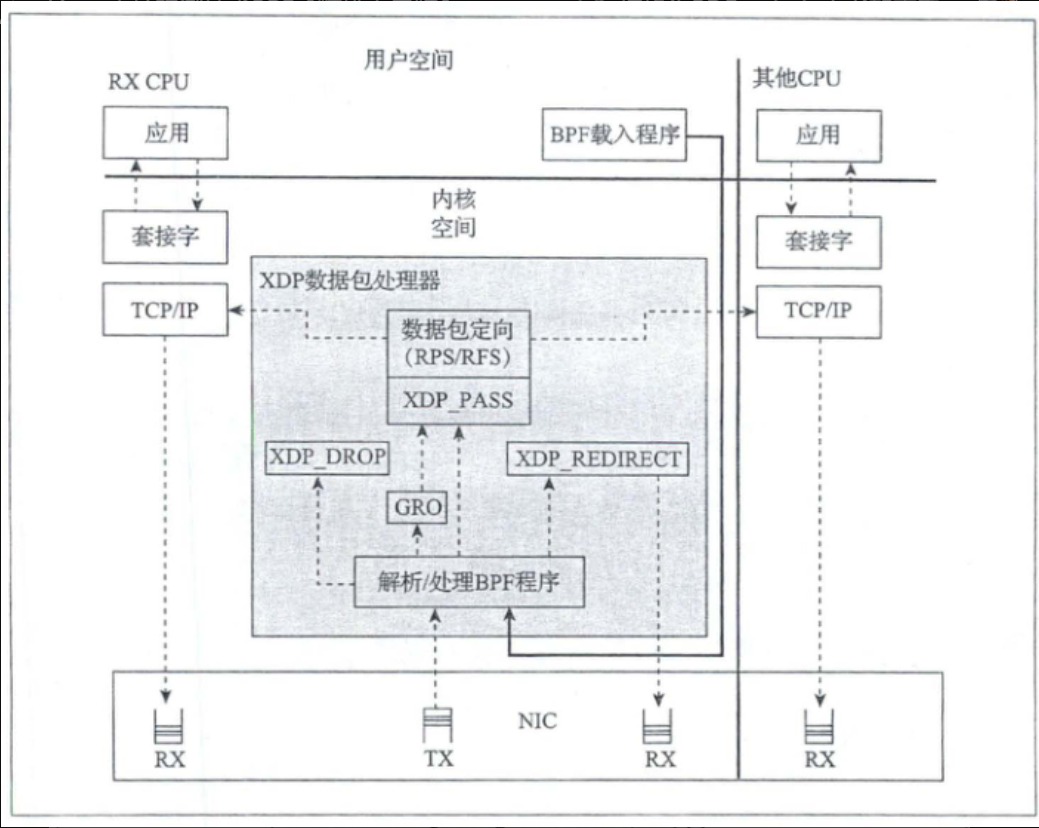
iproute2中提供的ip命令具有充当XDP前端的能力,可以将XDP程序编译成ELF文件并加载它,并且王权支持映射,映射重定位,尾部调用和对象持久化。 加载XDP程序:
ip link set dev eth0 xdp obj program.o sec mysection
卸载附加的程序并关闭设备的XDP:
ip link set dev enpos8 xdp off
XDP 用户案例
监控
如今,大多数网络监控系统都是通过编写内核模块,或者从用户空间访问proc文件实现的。 DDos攻击缓解
XDP能够在网卡NIC级别查看数据包,这可以确保任何可能的数据包在第一阶段被拦截,在这个阶段进行来接保障系统无须花费计算能力分析数据包是否对系统有用。
负载均衡
XDP只能在数据包到达相同网卡上重新传输数据包。
防火墙
Linux 内核安全、能力和Seccomp
能力
在程序未授权suid或者进程未授予特权的前提下,Linux的能力可以赋予程序特定能力以完成特定任务,从而降低攻击风险。
能力通常用于容器运行时,如runc或Docker,大多数应用程序能够以非特权容器运行,同时,允许指定容器所需的能力。
docker run -it –rm –cap-add=NET_ADMIN ubuntu ip link add dummy0 type dummy
Seccomp
Seccomp是Secure Comuting的缩写, Seccomp是Linux内核中实现的安全层,用于开发人员过滤特定的系统调用。
如果Seccomp采用SECCOMP_MODE_FILTERM模式,那么Seccomp过滤将采用基于BPF过滤器的方式对系统调用进行过滤,系统调用过滤的方式与数据包的过滤方式相同。